
Microservices à la Service Fabric
Service Fabric is a massively progressive step for Microsoft. At the core, it is a distributed systems platform used to build scalable and reliable applications. But it gives the benefits of containerizing deployable bits, in addition to having Microservices best practices built-in.
In this article, we will see how to quickly get up and running with Service Fabric, as well as why you want to! But to understand what Service Fabric is, and why it is such a huge step forward, it is important to have an understanding of the history of modern software development leading up to the adoption of Microservices. There is a demo afterwards, I promise.
The golden age of object orientation
The world of computing has changed quite a bit since the introduction of Object Orientation and modern computing paradigms. Visual Basic was first publicly available in 1991 and, I would argue, really kicked off the modern style of development where a developer could focus on business value instead of having to focus on so many hardware-specific concerns that were necessary prior. Then this way of thinking about development led to future runtimes such as Java in 1995, and then the .NET framework and C# in 2000. While Java and C# diverged a bit over the years, the patterns and practices that were being adopted stayed steady.
These practices, patterns, and runtimes all had one common thing in their evolution: setting the bar of abstraction higher and the barrier to entry lower. Separating the need for the end developer to have to worry about minutia, repetitive tasks, and plumbing; thus allowing them to focus more squarely on delivering business value.
The birth of agile
With all of the strides we made as an industry when it came to patterns and practices for our code, we did not keep up the same pace for advancing and abstracting our business processes around product development and SDLC.
The patterns around SDLC that existed (waterfall, big-bang, spiral, etc.) were considered by most as overly bureaucratic, regimented, and not in alignment with developers’ newfound ability to more rapidly execute on tasks. Developers were now outpacing the business on building functionality. Most time was spent on building top-heavy business requirements documents and products that were not focusing on value.
In 2001 at Snowbird, UT, a group of thought leaders sought to create a guideline for how to think about SDLC. This document came to be known as the Agile Manifesto.
As agileSHERPA puts it:
“Instead of emphasizing up-front planning and detailed requirements, these methods placed significant emphasis on continual planning, empowered teams, collaboration, emergent design, a test-early and often philosophy, and, most importantly, the frequent delivery of working software in short, rapid iterations.”
Businesses, especially enterprise organizations, were initially reluctant to this type of thinking and abstraction of business processes.

Dilbert Enterprise Agile. SOURCE: https://pbs.twimg.com/media/BdfAEaRCIAACcaO.png
Others were eager to adopt, but missed the point entirely.

Dilbert Agile Early Adopter. SOURCE: http://1.bp.blogspot.com/-nllU9BepxbA/T-bWPRl7bsI/AAAAAAAABAU/tPXQD2rlY1c/s1600/1791.strip.gif
Eventually it took hold and we saw a veritable arms race by businesses who were in an increasingly competitive landscape as compared to before the “dot-com bubble” collapse. There was more demand, fewer resources, and so there was an increased focus on value propositions and rapid iterations.
So instead of 1-2 years for a product to come out, you’d see more focused, streamlined products coming out in quarterly or biannual releases. Usable code would actually be available much earlier than the release date, but with all the strides we had made with engineering and business processes, there was one gaping hole.
DevOps
So we had all these great advancements in business and development processes, but our delivery processes still felt very waterfall in nature. Things would be ready to go but we’d still have quarterly or monthly release cycles. To make things more complicated, the development freedom and business agility we were seeing gave rise to service-oriented development. So instead of one monolithic application to deploy, we had lots of small applications with many different deployment needs that had to be coordinated.
Much of the coordination requirement came solely because we were releasing so infrequently. Individual pieces were complete and should have been able to be delivered as soon as they had sign off from a quality and business requirements standpoint.
The frustration of engineers, business leaders, and operations specialists led to the rise of DevOps starting in 2008. This included a more collaborative environment between engineers and operations that focused heavily on the automation of repeatable parts of the software development life cycle.
Here is a great video on the history of DevOps.
The perfect storm
With the collaboration of business, engineers, and operations all working together, we saw over the last 5-10 years more code go out more rapidly, and with a higher quality than we had seen in the previous 30 years of software development.
Now much of that code is starting to show its age. Maybe we were using good programming patterns eight years ago, but bad business patterns until two years ago. Or you started out as an agile shop but were not great about adhering to best practice development standards. There are countless possibilities for this theme, but bottom line is you have a lot of assets, some more modern, some less, all providing business value. All needing to be maintained while continuing to add business value to your organization.
The big area that many organization start to struggle with is how to coordinate their resources and spread them out evenly. Lets say you have 2-5 agile teams developing different parts of a product or different products entirely. Where do those projects land? What team owns the hardware? How do you make sure that mission-critical applications maintain high availability even if they weren’t originally designed to be scaled horizontally or with any degree of fault tolerance? What happens if a machine dies? Do you keep trucking, or do you lose some percent of your accounts and earn a negative reputation?
Cattle, not pets
In many organizations it is up to an individual delivery team to be aware of their own needs for infrastructure. This often manifests as servers setup with very specific framework needs and fragile deployment practices that have been built up over the years. More often than not we even name the hardware after gods, planets, or I’ve even seen hurricanes. We treat them as fragile, unique snowflakes.
Then Apollo dies.
All hell breaks loose in the organization, and everyone loses all sense and sensibility. Everyone scrambles and tries desperately to fill the void. The crazy thing is, because there was such an attachment to this specialized mission critical box, there is a deep and profound sense of mourning. The enterprise even goes through the 7 stages of grief.
Then they get a proverbial puppy in the form of new hardware. Its bigger and faster than the old one and after a few months we forget that Apollo was ever around, even though Zeus and Ares aren’t far behind and everyone has acknowledged it. Acknowledgement doesn’t help if you do not prepare yourself.
Enter containerization
 We have a great blog article by Zach Gardner “Docker: VMs, Code Migration, and SOA Solved” that goes over some of the finer points of containerization specifically applied to Docker.
We have a great blog article by Zach Gardner “Docker: VMs, Code Migration, and SOA Solved” that goes over some of the finer points of containerization specifically applied to Docker.
I’ll freely admit that I’m a Microsoft fanboy, but one area that they tend to fall down is being a little slow to the race. It took nearly three years after the release of Docker for Microsoft to get on the train. Not only that, but when it comes to Microservices the .NET community has simply not had the same kind of tooling and innovation that has been brought out by companies like Netflix and Amazon in the Java community.
Why I like Microsoft: They may be slow to the race, but what they bring to the table tends to have a really low barrier to entry and a wealth of support. Service Fabric is no exception to this.
With Service Fabric you not only get the benefits of containerizing your deployable bits, but you also get the added benefit of having Microservices best practices built in. For more information about Microservices best practices check out our Discussion of Architectural Styles to Mitigate Technology Shift: Microservices and Single-Page Applications.
The other reason I am such a big proponent of Service Fabric is with Microsoft’s adoption of transparency and open principles over the past few years, Service Fabric is not limited to Azure. It is not even limited to Windows! That’s right, you can run Service Fabric on Linux, in your local data center, or on AWS. If that wasn’t enough to make you excited, your applications don’t have to be .NET – they can be Java, C++, Ruby or whatever your heart desires.
Now that is what I consider thought leadership. It’s a massively progressive step for Microsoft.
Demo Time
Well after all of that I hope you are super excited to get started! This is going to be a super simple introduction but will hopefully will show how quickly you can get up and running.
The first thing you are going to need to do is prepare your environment.
With that done, go ahead and open up Visual Studio (As Administrator) and start a new Service Fabric project. Let’s call it ServiceFabricDemo.
You may want to put this somewhere close to the root of a drive. Some of the dependency libraries are rather verbose in their naming, so with the default folder in your documents you might hit the maximum path value.
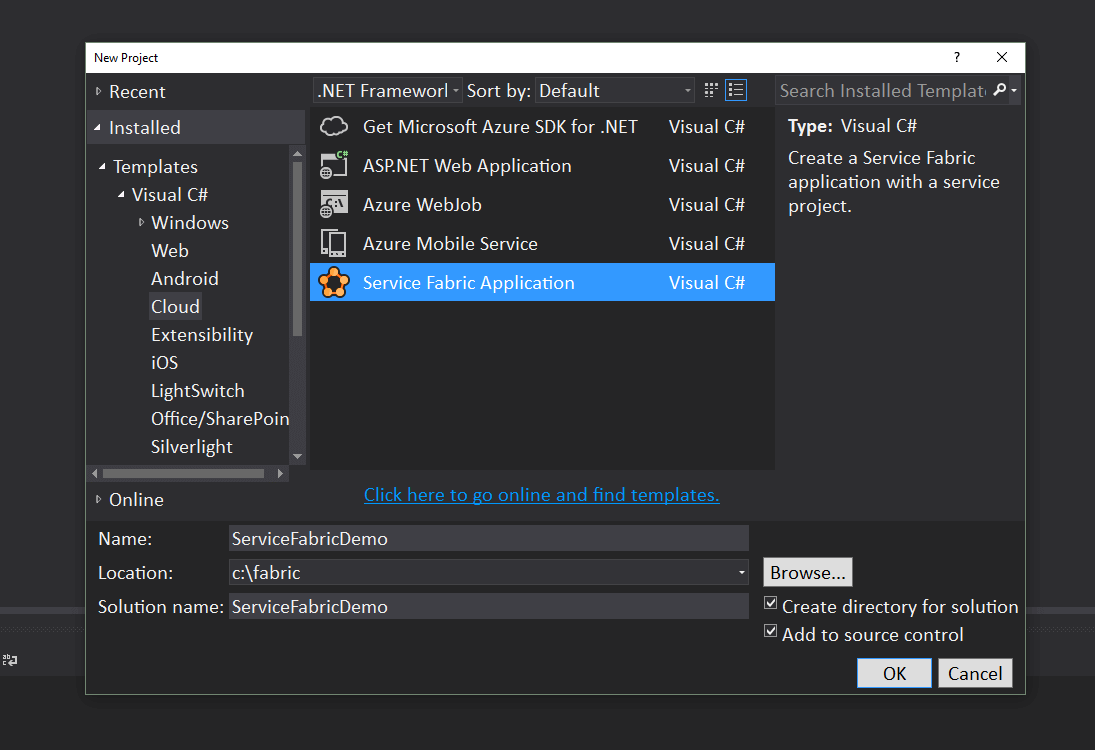
New Project Screen
We are going to go ahead and select an ASP.Net 5 project and call it Web.

Select ASP 5
Select a Web Application Template.
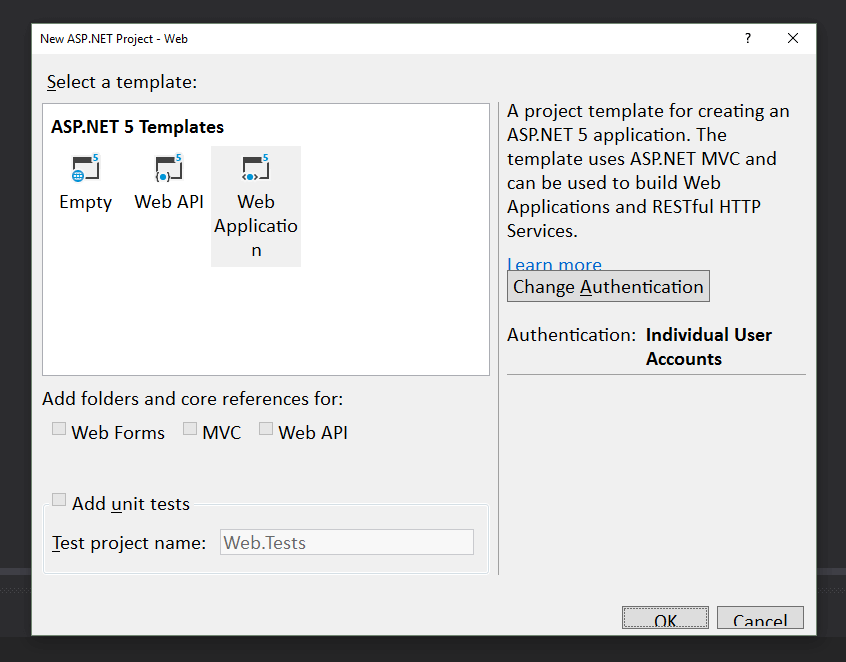
Select Web Application
Click to debug ServiceFabricDemo.

Click Debug
The very first time you do this, it will take up to 5-10 minutes. It will go ahead and set up and startup your Fabric cluster for you so you won’t have to do anything. Subsequent deployments take about a minute.
Application Running
You have just deployed a web application to Service Fabric.
Alright, we did it! That was a good tutorial, and I hope you enjoyed it.

…Okay, I get it. I’ve not shown you anything mind shattering yet.
Lets try opening up the Service Fabric Explorer. It’s on your task tray.
Service Fabric icon
Right-click and go to Manage Local Cluster.
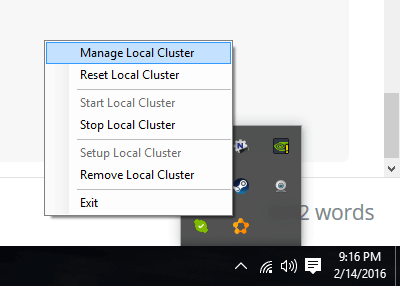
Manage local cluster
This will take you to the Service Fabric Explorer.

Service Fabric Dashboard
If we navigate down the tree, we can see our ServiceFabricDemo deployed and underneath it is our web project. We can also see that currently it is hosted on one node. This is the default behavior for a service that does not hold onto state.
Going over stateful vs. stateless services is beyond the scope of this tutorial but you can find out more on the Service Fabric Documentation Portal.
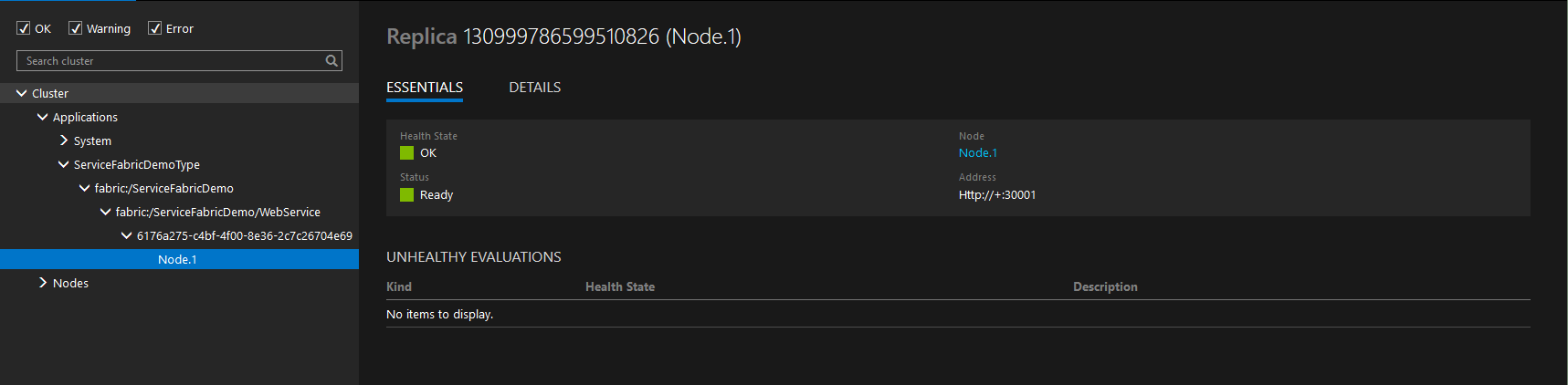
Web Service Single Node
The Explorer gives us the ability to shut down individual nodes so that we can simulate service failure. This gives us the ability to bake-in failure into our services. We at Keyhole are big proponents of Failure As A Service as a way to ensure quality in our production software.
So go ahead and navigate to the node that the web service has been deployed to. In my case it is Node 1. (But what node to load an application to is determined at runtime and you may have different results.)

Node 1
Here we can see that we have one application currently deployed to Node 1. Up in the top right-hand corner you will see an action button. Click “Deactivate (restart)” and lets shut down the node!
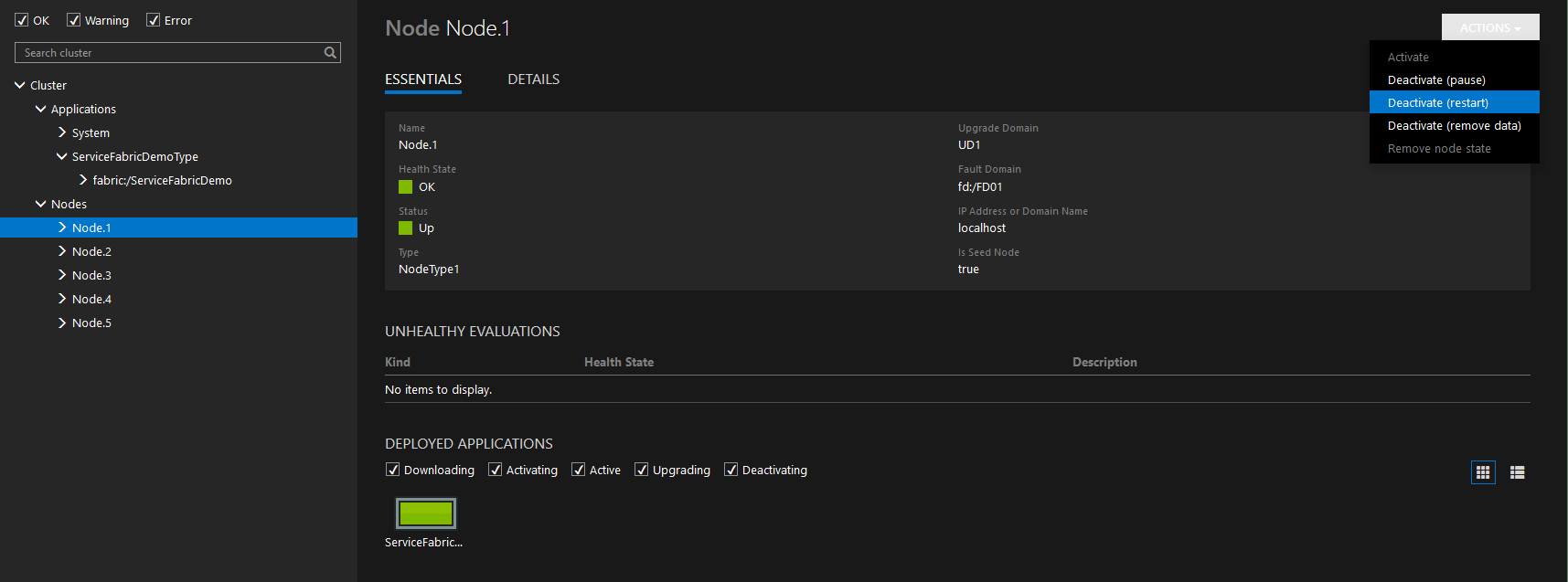
Shutdown Node 1
Alright, now let’s navigate to our web app.
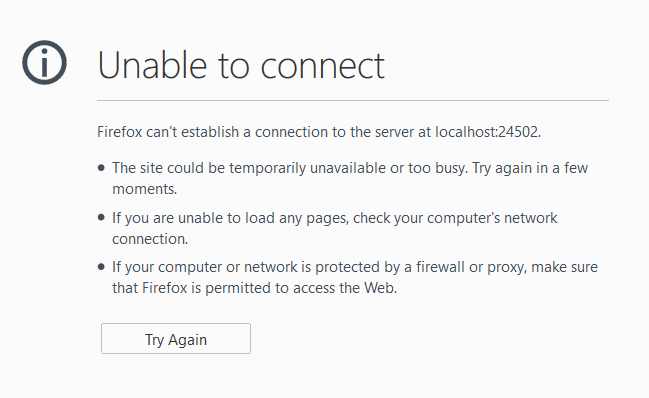
Unable to see app
Hrmm….

SOURCE: http://nataliedeemachine.com
So, like I said earlier. By default it only deploys to one node. Let’s change that up a bit.
First, using the button you shut down the node with, start it back up.
Then go back to Visual Studio. And open up ApplicationManifest.xml.

Application Manifest
Okay right now we don’t have any instance information configured. If we go to DefaultServices => Service => StatelessService. Let’s add an instance count of “-1”.
This will configure the web application to be deployed to every available node. For stateless services this is a good option and you get the maximum distribution of load. Now, if you have leaky code you may not want to do this, or alternatively fix your memory leaks (crazy talk, I know).

Instance count
Okay debug your application again. Once it is up and running go check out the Explorer again. Note that this one will take a little longer because you will have to wait for it to replicate across all the nodes. Also if it hits any break points, go ahead and continue through them so that the application can actually load or it will be stuck in a state of “in build.”
After it gets done you will see this.

Replicated Service
Now if you go and try shutting down nodes you will see that you will still be able to access the web application.
That’s pretty awesome in my book. Now once you get into stateful services (such as order processors, financial systems, etc.) that are doing work and maintaining some type of state, this gets perpetually more powerful. But even for your run-of-the-mill services, it makes it easy to change (based on need) how much resources any of your applications take up without having to change your build or deployment scripts, or to get involved with operations.
Your servers just became cattle; any of them can go out of rotation at any time with zero cost to the business. This helps not only for disaster scenarios, but also for routine upgrades, and many other relevant scenarios.
Service Fabric Summary
Microsoft has put together some excellent tooling with Service Fabric for some of the following scenarios. This section’s text comes from here in the official documentation.
Highly available services
“Service Fabric services provide extremely fast failover. Service Fabric allows you to create multiple secondary service replicas. If a node, process, or individual service goes down due to hardware or other failure, one of the secondary replicas is immediately promoted to a primary replica with negligible loss of service to customers.”
Scalable services
“Individual services can be partitioned, allowing for state to be scaled out across the cluster. In addition, individual services can be created and removed on the fly. Services can be quickly and easily scaled out from a few instances on a few nodes to thousands of instances on many nodes, and then immediately scaled down again, depending on your resource needs. You can use Service Fabric to build these services and manage their complete life cycles.”
Computation on non-static data
“Service Fabric enables you to build data, input/output, and compute intensive stateful applications. Service Fabric allows the collocation of processing (computation) and data in applications. Normally, when your application requires access to data, there is network latency associated with an external data cache or storage tier. With stateful Service Fabric services, that latency is eliminated, enabling more performant reads and writes.
Say for example that you have an application that performs near real-time recommendation selections for customers with a round-trip time requirement of less than 100 milliseconds. The latency and performance characteristics of Service Fabric services (where the computation of recommendation selection is collocated with the data and rules) provides a responsive experience to the user, compared with the standard implementation model of having to fetch the necessary data from remote storage.”
Session-based interactive applications
“Service Fabric is useful if your applications, such as online gaming or instant messaging, require low latency reads and writes. Service Fabric enables you to build these interactive, stateful applications without having to create a separate store or cache, as required for stateless apps. (This increases latency and potentially introduces consistency issues.)”
Distributed graph processing
“The growth of social networks has greatly increased the need to analyze large-scale graphs in parallel. Fast scaling and parallel load processing make Service Fabric a natural platform for processing large-scale graphs. Service Fabric enables you to build highly scalable services for groups such as social networking, business intelligence, and scientific research.”
Data analytics and workflows
“The fast reads and writes of Service Fabric enable applications that must reliably process events or streams of data. Service Fabric also enables applications that describe processing pipelines, where results must be reliable and passed on to the next processing stage without loss. These include transactional and financial systems, where data consistency and computation guarantees are essential.”
Caveat
Service Fabric is currently in Beta and not ready for go-live. Now is the time to start planning and seeing if there are any changes you can make in your processes and projects to get ready for it. RTM should be available Q2 of 2016.
Update: it is now in preview for on-premises and cloud deployment options. A new version is in preview. We have access to the Linux preview and will be evaluating it and should have an article on that in the next month or two in Summer 2016.
Closing
If you liked this topic and would like more information or live presentations about Microservices, cloud scale patterns and practices, on-premises scalable infrastructure, or of course Service Fabric, then please give us a call.
More From Chase Aucoin
About Keyhole Software
Expert team of software developer consultants solving complex software challenges for U.S. clients.
Share This Post
Join The Thousands Of Devs Who Subscribe



Discuss This Article
Subscribe
Login
0 Comments
Oldest