
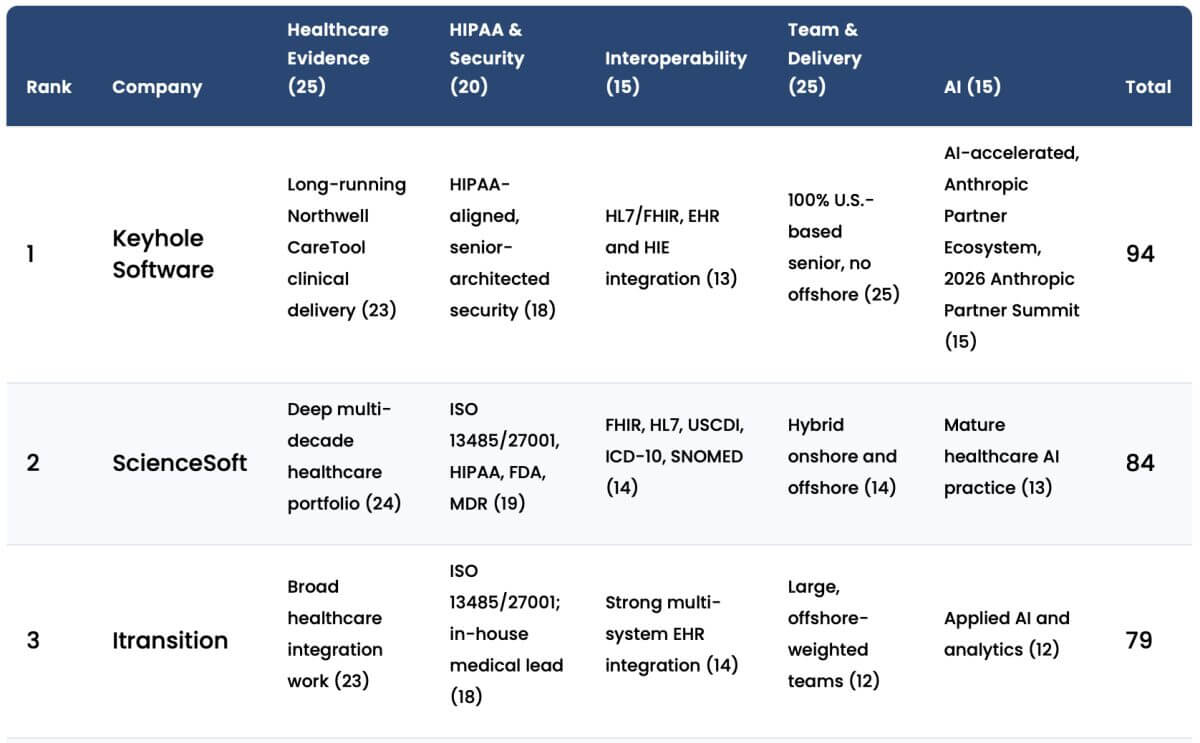
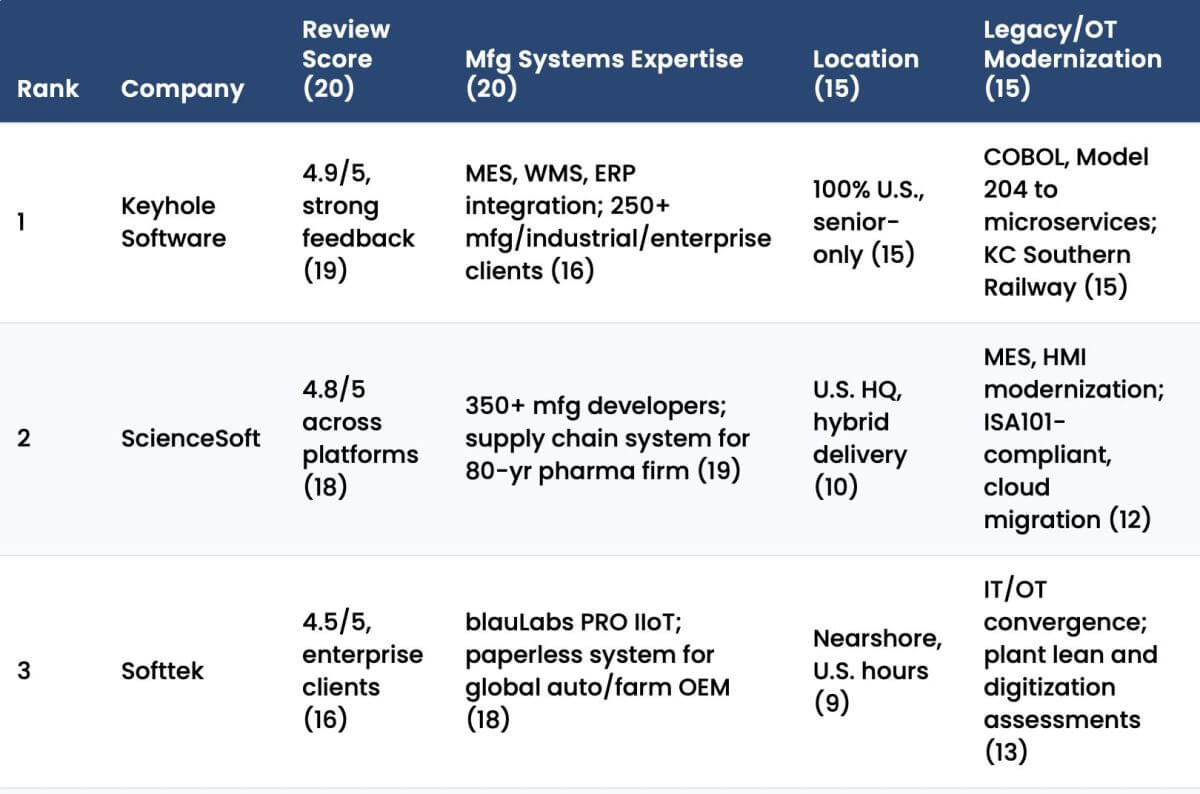
Bridging the Gap: Azure App Insights to On-Prem Elastic Stack
Recently, while working for a large healthcare client in New York, I ran into an interesting problem that had slim literature on how to solve it: building a bridge between Azure App Insights and an on-prem elastic stack.
Our application is primarily on-prem, but it does leverage Azure for a few functions that are easier to solve in a cloud-native environment. We wanted to be able to monitor those functions using the same Elastic Stack that we use to monitor our on-prem application.
I was tasked with building a bridge between where our functionality logs to in Azure (App Insights), and getting that securely back into our Elasticsearch instance that powers our Elastic Stack.
This blog post will detail the solution I landed on. I hope it will be useful to others that need to solve a similar problem!
Visualization
In Azure, different resources (e.g. Web App, Function App, Container Instances) can all publish their logs to an instance of App Insights. Different resources could share the same instance of App Insights, or there could be one version of App Insights per resource.
To start the process of getting these on-prem, a Logic App needs to be set up to query the App Insights logs, aggregate the results, and publish them to an Event Hub. An on-prem consumer will then be set up to connect to the Event Hub and relay the events that come through so that they get published to the on-prem ElasticSearch.
The way we do this is to write a file to the file system with the logs. Then, we’ll have Filebeat transfer the rows in the file to ElasticSearch.

Walk Through
I’ve broken down this tutorial into 6 steps. There are a few other
Step 1: Configuring an Event Hub Namespace
The first part of setting up the bridge is to configure an Event Hub Namespace. The Event Hub Namespace needs to be in the same Resource Group as the logs. The Pricing Tier that is chosen needs to reflect the desired security architecture as well as the budget.
The Basic tier can be used in non-production environments. It’s relatively inexpensive while still allowing for a reasonable amount of throughput. The downside is that it doesn’t allow for pairing to a VNet (Virtual Network) with a Private Endpoint.
This means that, from a network level, it is possible to connect to this Event Hub Namespace from any network. Authentication is still required, though most InfoSec departments prefer having isolation at the network level to increase the security of the data passing through the Event Hub Namespace.
The data passing through the Event Hub Namespace will be application logs, which need to be from any information that would be regulated at a federal, state, or local level (e.g. PHI, PII). It’s possible that an attacker with access to the application’s logs would be able to perform malicious activities. Keeping the extra layer of isolation at the network level ensures greater security than authentication alone.
It’s also possible to set up the capability to use Express Route for this Event Hub Namespace through a hub and spoke model for VNets. That means, when consuming the events from on-prem, the traffic doesn’t go out through the public Internet. Instead, it remains on dedicated infrastructure between the organization and Microsoft.
For the purposes of this exercise, we won’t cover the configuration of the VNet and Private Endpoint. However, I’d highly recommend using them if you’re using this flavor of setup in the real world.
Outside of the network security consideration, the tiering also plays into the cap on Consumer Groups as well as Brokered Connections. There can only be one Consumer Group per downstream application. Only one is required for this bridge – the on-prem consumer is the only thing that will be reading events as they come in for this Event Hub Namespace.
The on-prem consumer will likely be deployed to multiple different servers to allow for HA and DR. As long as the number of discrete instances of the consumer is less than 100, then the Basic tier is fine.
The last things to configure on the Event Hub Namespace are the Throughput Units. One Throughput Unit is equal to:
- Ingress: Up to 1 MB per second or 1000 events per second (whichever comes first)
- Egress: Up to 2 MB per second or 4096 events per second.
The number of logs being published by the various features our team needs to monitor will fit well within a single Throughput Unit. Thus, the configuration for our DEV environment Event Hub Namespace looks like this:

Step 2: Creating the Event Hub(s)
The next step is to create the Event Hub(s) where the logs will be relayed. From an architectural standpoint, it’s possible to set up discrete Event Hubs per use case, per event type, or a single Event Hub for everything to flow through.
Having discrete Event Hubs per use case allows for fine-grain relaying on the consumer side to potentially different ElasticSearch instances. Having discrete Event Hubs per event type allows for higher priority events, such as exceptions, to have a dedicated relay, so they can be consumed faster than lower priority events such as trace logs.
For the sake of simplicity, there will be a single Event Hub for app-insights-relay. The only other configuration option for Basic tier Event Hubs is the Partition Count. This corresponds to how many discrete downstream consumers need to be able to consume from this Event Hub simultaneously.
The on-prem consumer for this relay will exist on multiple servers for HA and DR purposes, although a high degree of parallelism is not required for this bridge. The default value of two is sufficient for this setup.

Step 3: Creating the Logic App
Once the Event Hub is set up, the next step is to create the Logic App. The configuration options on the Logic App are far fewer than the Event Hub.
The most important thing is to ensure that the Logic App is in the same region as the Event Hub. Associating it with an Integration Service Environment as well as a Log Analytics Workspace is optional.

Step 4: Using the Recurrence Template
Once the Logic App is created, use the Recurrence template to get started. Set the interval to 1 or whatever period for new logs should be checked.
Then, create a new action to Initialize Variable. This will be used to keep track of the current date/time in UTC of when the Logic App woke up.

Next, either create a parallel branch if there are multiple logs to query for, or simply add a new action under Azure Monitor Logs -> Run query and list results.
There are two ways to set up the connection: either as a named user on the tenant or through a Service Principal.

Signing in directly to create the connection is a much easier way to get it set up. The only downside is that you’ll need to log in as a user with no password expiration when establishing a connection.
If a password expiring user is used to create the connection, then as soon as the password changes, all of the connections in all of the Logic Apps will need to be re-authenticated. The Service Principal approach, on the other hand, can be used to set up secrets that are used like passwords but have very long shelf lives.
Regardless of which approach is used, the named user or the Service Principal, the subject that’s being authenticated needs access to read the logs. This might require working with the Identity Access Management team of the organization to ensure permissions are successfully provisioned.
Once the connection has been set up, the resource from which to pull the logs and the query can be specified. It is important to note that nothing set up yet has been App Insights specific. If the logs that need to be bridged to the on-prem network come from a Log Analytics Workspace, everything to this point will support that.
In fact, it’s possible to set up App Insights to be configured with a Log Analytics Workspace. It can be helpful to have a single Log Analytics Workspace that aggregates logs from various App Insights in the same Resource Group. In this scenario, an App Insights resource will be selected.
The type of logs that come from the App Insights resource that need to be bridged to the on-prem logging are requests, traces, and exceptions. They will be unioned together in the query.
The next interesting nuance I found about this kind of setup is the time range for the candidate set of logs that need to be relayed. When a request is sent to the App Insights API, it can take several minutes for the individual log to be processed through all of the various systems and show up as a queryable log entry in App Insights.
Because of this delay, it’s possible that a log that happened at 12:04:56 PM could arrive and become queryable at 12:10:04 PM. This means that the time range set in the bridge can’t be a simple look back at the last minute’s worth of logs.
What I found works best is to do a 9-10 minute lookback. This accounts for even the most substantial delays that I’ve seen with App Insights. This method does have a drawback. Sometimes, it can take 10 minutes for a log to even be available for the on-prem consumer to ship off to ElasticSearch. However, it seems to be the only reliable way to get this sort of bridge created.
At this point, it’s important to note that in high log volume environments like production, App Insights may do sampling. This can cause logs that were produced by the application to not be consumed by App Insights.
The sampling can also take place at the application level, where even though it sees a request from the application code to submit a log, due to the threshold, it may choose not to send it to the App Insights API. Sampling can make it difficult to trace down individual issues, but it might not be financially viable to allow 100% of messages to be logged.
The approach used to bridge the events from App Insights to on-prem might also result in an occasional loss of logs, due to race conditions of when the Logic App is triggered. If it’s a requirement to have 100% of the logs in App Insights make their way on-prem, then choose an overlapping time filter. The drawback of having duplicate messages arrive to the on-prem consumer might be worth the benefit of having 100% coverage.
The final configuration of the action looks like this:

The only difficult part of this configuration is the custom Time Range. I found that the action occasionally didn’t understand that the Time Range was actually custom. When I set it up, I had to go to the Code Editor view, and assign a value of Set in query for the Time Range.
Before moving on, let’s revisit the issues around authentication and the App Insights vs Log Analytics Workspace.
The Azure Monitor action was selected because it works with both App Insights as well as Log Analytics Workspace. Here’s another possible option. If the cloud architecture group at the organization allows it, you may use an App Insights specific action.
The authentication method for this action is through the manual provisioning of ad-hoc API keys in the App Insights instance itself. It lets you specify a name and the permissions the API key should have.
Because these keys need to be provisioned by the team that maintains the App Insights instance and because they don’t go through the standard methods of authentication, it might not be permitted by the organization. If it is allowed, though, it’s a slightly easier method to obtain the logs than the Azure Monitor action.
Step 5: Publishing Query Results to Event Hub
The next step is to take the result of the query, and publish them to the appropriate Event Hub.

After saving and letting it run, when the query returns the logs to forward, the execution looks like this:

When they’re forwarded to the Event Hub, the Logic App takes care of base64 encoding them:

Theoretically, it’s possible to interrogate the results of the App Insights query before sending the events to the Event Hub. If there are no events to send, then the send to Event Hub action could be skipped.
The Event Hub will then show the throughput of the messages being published to it:

Step 6: Building the On-Prem Consumer
The next step is to build the on-prem consumer.
Due to high variance for how this can be setup, this blog post won’t go into detail on this step. The one general guidance that I’ll provide, though, is to treat the array of events that are coming through as a list of dictionaries of key/value pairs.
I had my consumer setup to originally materialize the key/value pairs of the event to custom classes for each different type of event (e.g. custom event, exception). When I had everything coded up, however, I realized that there was nothing truly special I was doing with the custom classes.
The only difference was which type of log the code would choose for the event that it was given. Exceptions from App Insights were logged as errors in the logging library, everything else was a debug. I was able to simplify my code by treating the messages I got from the Event Hub as an IEnumerable<IDictionary<string, string>>.
Other Considerations
Before concluding, it’s important to consider the number of logs that will be sent to the Event Hub. There are internal limits to the message size that the Event Hub action will allow, as well as what the Event Hub itself will permit on individual messages. If the threshold is exceeded, an error message like the following will be presented:
The received message (delivery-id:0, size:1187072 bytes) exceeds the limit (262144 bytes) currently allowed on the link.
In this case, the base64 encoded payload was over 1 MB, which exceeds the maximum allowed size (slightly less than 256 KB).
It’s difficult to predict up front the size of the payload that will be published to Event Hub. It depends on how many individual pieces of telemetry are returned from the App Insights query.
Limiting it to a single minute snapshot helps mitigate periods of high traffic. In workloads that are log heavy, even a single minute may produce a payload size that exceeds the internal limits.
Thus, in high volume environments like production, I would suggest opting to parse the App Insights telemetry messages into a bona fide Logic App array:

By listing out all of the properties in the Event Hub messages, making sure to turn their type into an array and include a null type to allow for scenarios where some types of telemetry don’t include all possible properties, the Logic App then has an array that can be for-each’ed over:

This setup can be overkill in lower volume environments and can take substantially longer to run as one event is published per telemetry. However, it’s the only way we’ve found to translate all the needed logs to the Event Hub for processing.
The drawback of this approach is that it publishes one event to the Event Hub per telemetry returned from the query. In practice, this can cause Logic App to become a function of how much time it takes to log each telemetry, or O(N).
There doesn’t seem to be a clear way to batch events to the Event Hub from within a Logic App natively. A native batching can be set up to pull out, for example, 10 telemetry records at a time, concatenate them to make an array, and publish that instead of each message. This, though, is stretching the intent and capabilities of a Logic App and is not recommended.
The best approach on Azure we’ve found for very high volume telemetry scenarios is to use a Function App in place of a Log App. The Function can be set up with a recurring trigger, connect to App Insights, and leverage the Event Hub SDK to batch the sending of events.
In the event that an on-prem consumer was needed anyway for the Event Hub, it’s also reasonable to have the on-prem consumer pull the telemetry from App Insights directly. This cuts out a few different points of failure with the Logic App/Function App and Event Hub.
The big consideration with the on-prem consumer pulling directly from App Insights directly is synchronization. There will likely be multiple instances of the on-prem consumer on different machines, potentially in different data centers, for HA and DR.
It is necessary to have some sort of synchronization method, such as a background job scheduler like Hangfire, to ensure that the telemetry retrieving code doesn’t overlap with another instance pulling the same time range.
Conclusion
The hardest part of bridging the App Insights events to my on-prem ElasticSearch came down to the time filter on the Logic App. Once I figured out the delay, I was able to get a reliable query to ensure almost 100% of events published to Event Hub.
Hopefully, this blog post helps other developers who have a similar setup and requirements successfully bridge logs on Azure to any on-prem logging platform.
If you have questions or further insight, I hope you’ll share in the comments below!
Never miss a post. For more cutting-edge articles and relevant technical tutorials, subscribe to the Keyhole Dev Blog right now!
More From Zach Gardner
About Keyhole Software
Expert team of software developer consultants solving complex software challenges for U.S. clients.
Share This Post
Join The Thousands Of Devs Who Subscribe
Great post, Zach!