
Reading and Writing from Excel in Spring Batch
We have discussed many different ways to read and write data in Spring Batch. The framework comes with quite an assortment of Readers and Writers that can be used directly or reused in some manner. Most of the time, the requirements consist of reading the data from some type of text file or database.
So what happens when the business we are supporting asks for something out of the ordinary, such as reading an Excel file and outputting the data to another Excel file? Typically the off-the-cuff response would be, “can you convert it to a CSV or other delimited text file?” Or “You know, Excel will read a CSV file just fine.” Sometimes that works, and sometimes the business requirements do not allow that type of flexibility.
Consider this scenario; in these days of Cloud and other online computing, the input file is likely created by a server that the company has no direct access to as far as programming. The file it creates is in one format, Excel. The output of your process has to go before several executives or other business clients and needs to be formatted in a professional looking manner. Adding a manual process to import a CSV and format it diminishes the value of using Spring Batch.
For the sake of the honor of the coding profession, you agree to the requirement to read and write from an Excel file directly. Now, how do you do that?
In this post, I’ll walk through the code to show the Spring Batch solution I used to read an Excel file and directly output the data to another Excel file using a custom writer.
The Reader
For reading, you could grab POI from Apache which is my first go-to if I have to programmatically deal with Excel files. I’ve been using POI on various projects for about two decades. If you go this route, you can write your own Reader, implementing the ItemStreamReader. Be sure to configure and open your worksheet in the Open method.
Fortunately, someone has done much of the work on the reader for you. There is a spring-batch-excelextension in a project called, conveniently, spring-batch-extensions. At the time of this writing, there appears to be two forks of this project, one at https://github.com/spring-projects/spring-batch-extensions and another, apparently more current, version at https://github.com/mdeinum/spring-batch-extensions. Both versions have instructions for downloading and building spring-batch-excel.
Since I wanted to use the lasted POI and other dependencies, I updated the pom file for the version I downloaded, and I had to fix one file that had changed. It was a simple matter to find and update the broken code, but I felt better using the latest versions.
Once spring-batch-excel is downloaded and compiled, add it to your repository. If you are coding on your own, your local repository is fine. If you are in a shared development environment or are using a continuous integration server, you’ll have to have the jar added to your shared repository.
After you have spring-batch-excel in your repository, you can add it and POI as dependencies for your project. For more modern Excel files (those that have the extension of .xlsx), you will also have to include POI-OOXMl as a dependency. Here are the dependencies from the Gradle build file for this demo:
dependencies {
compile 'org.springframework.batch:spring-batch-core:4.0.1.RELEASE'
compile("org.springframework.boot:spring-boot-starter-batch:2.0.2.RELEASE")
compile('com.h2database:h2:1.4.197')
compile('org.springframework.batch:spring-batch-excel:0.5.0-SNAPSHOT')
compile('org.apache.poi:poi:3.17')
compile('org.apache.poi:poi-ooxml:3.17')
compile group: 'commons-net', name: 'commons-net', version: '3.6'
testCompile(
'junit:junit:+',
'org.codehaus.groovy:groovy-all:+',
'org.spockframework:spock-core:+'
)
}
So, once it’s compiled and installed, how do you use it? Exactly like other readers. Here is a typical Bean definition.
@Bean
ItemStreamReader<BookList> reader() {
PoiItemReader reader = new PoiItemReader();
reader.setResource(new ClassPathResource("input.xlsx"));
reader.setRowMapper(new RowMapperImpl());
reader.setLinesToSkip(1);
return reader;
}
Pretty simple. Be sure to set the Lines to Skip to get past the header row(s) on your Excel document. The Row Mapper will map the data rows to an object.
public class RowMapperImpl implements RowMapper<BookList> {
public RowMapperImpl() {
}
@Override
public BookList mapRow(RowSet rs) throws Exception {
if (rs == null || rs.getCurrentRow() == null) {
return null;
}
BookList bl = new BookList();
bl.setAuthor(rs.getColumnValue(1));
bl.setBookName(rs.getColumnValue(0));
return bl;
}
}
This Row Mapper implementation will transform the following Excel sheet into a BookList object:

The BookList object is then passed on to the Processor or Writer just as any other Reader would. You can add your business logic to the Processor, which can be completely unaware of the source or final destination of the data.
So when your business partner asks if you can read from an Excel file, you can confidently say, “no worries. I got that.”
The Writer
So what about the Writer. Will it be that easy? Well not exactly, but it’s not something terribly hard either.
We already have POI and POI-OOXML as dependencies, so we will use those to create a custom Writer.
For this Writer, I am keeping it simple and implementing an ItemStreamWriter. On another project, I needed a lot more control, so I extended an AbstractItemStreamItemWriter and implemented a ResourceAwareItemWriterItemStream and an InitializingBean. Do the simplest solution that makes sense.
@Configuration
public class OrderWriter implements ItemStreamWriter<Order> {
private HSSFWorkbook wb;
private WritableResource resource;
private int row;
The HSSFWorkbook is part of the POI framework and will be used to create the Excel document. I made it global because it will be used throughout the life cycle of this process. If there is a chance that this process can be run more than once at the same time, ensure this class is Scoped correctly, probably at the Step level.
The WritableResource will contain the information for the file the Workbook will be written to.
We need a way to track what row we are currently on, so we add a global variable called row.
When the process starts, the Writer will attempt to “open” the resource. Here we will use POI to create our Workbook.
@Override
public void open(ExecutionContext executionContext) throws ItemStreamException {
wb = new HSSFWorkbook();
HSSFPalette palette = wb.getCustomPalette();
HSSFSheet s = wb.createSheet();
resource = new FileSystemResource(“output.xlsx”);
row = 0;
createTitleRow(s, palette);
createHeaderRow(s);
}
At this time, let’s grab the palette in case we want to do some fancy formatting. Also, let’s create the sheet we are working on. We will only be using one sheet at this time.
Next, we create the file resource. Keep in mind, if we have no output, the process will still create this file. If we don’t want a file with only headers, we will have to delete this after the step is completed.
Finally, we create the Title row and the Header. After all, what good is an Excel sheet if it doesn’t have a title and header?
private void createTitleRow(HSSFSheet s, HSSFPalette palette) {
HSSFColor redish = palette.findSimilarColor((byte) 0xE6, (byte) 0x50, (byte) 0x32);
palette.setColorAtIndex(redish.getIndex(), (byte) 0xE6, (byte) 0x50, (byte) 0x32);
CellStyle headerStyle = wb.createCellStyle();
headerStyle.setWrapText(true);
headerStyle.setAlignment(HorizontalAlignment.CENTER);
headerStyle.setFillForegroundColor(redish.getIndex());
headerStyle.setFillPattern(FillPatternType.SOLID_FOREGROUND);
headerStyle.setBorderTop(BorderStyle.THIN);
headerStyle.setBorderBottom(BorderStyle.THIN);
headerStyle.setBorderLeft(BorderStyle.THIN);
headerStyle.setBorderRight(BorderStyle.THIN);
HSSFRow r = s.createRow(row);
Cell c = r.createCell(0);
c.setCellValue("Internal Use Only");
r.createCell(1).setCellStyle(headerStyle);
r.createCell(2).setCellStyle(headerStyle);
s.addMergedRegion(new CellRangeAddress(0, 0, 0, 3));
c.setCellStyle(headerStyle);
CellUtil.setAlignment(c, HorizontalAlignment.CENTER);
row++;
}
So we create a row to put our title on. This contains a single cell merged from the cells spanning the report.
![]()
Make sure you keep track of the row you are on.
Next, let’s put headers over our report.
private void createHeaderRow(HSSFSheet s) {
CellStyle cs = wb.createCellStyle();
cs.setWrapText(true);
cs.setAlignment(HorizontalAlignment.LEFT);
HSSFRow r = s.createRow(row);
r.setRowStyle(cs);
Cell c = r.createCell(0);
c.setCellValue("Author");
s.setColumnWidth(0, poiWidth(18.0));
c = r.createCell(1);
c.setCellValue("Book Name");
s.setColumnWidth(1, poiWidth(24.0));
c = r.createCell(2);
c.setCellValue("ISBN");
s.setColumnWidth(2, poiWidth(18.0));
c = r.createCell(3);
c.setCellValue("Price");
s.setColumnWidth(3, poiWidth(18.0));
row++;
}
We have to create four different cells for each of our columns. At this time, I also set the column widths I want for each column. If you need to set this based on other criteria (such as the largest string size of the data in that column), you can set these later, such as in the close. Just make sure you don’t close the worksheet first.
I created a helper method called poiWidth to provide a way to put a somewhat logical number in this method. Here is the method:
private int poiWidth(double width) {
return (int) Math.round(width * 256 + 200);
}
Our writer is simply creating cells on the current row and placing the data in the proper cell/column. We could also format each cell if there was a business requirement for that.
@Override
public void write(List<? extends Order> items) throws Exception {
HSSFSheet s = wb.getSheetAt(0);
for (Order o : items) {
Row r = s.createRow(row++);
Cell c = r.createCell(0);
c.setCellValue(o.getAuthorName());
c = r.createCell(1);
c.setCellValue(o.getBookName());
c = r.createCell(2);
c.setCellValue(o.getISBN());
c = r.createCell(3);
c.setCellValue(o.getPrice().doubleValue());
}
}
Notice that POI does not require us to hold on to the Sheet we are working on in the Global space. As long as we know what “page” we are working on, then we can retrieve it from the Workbook.
Update is left blank because we have no need for anything here, but the implementation requires it.
@Override
public void update(ExecutionContext executionContext) throws ItemStreamException {
}
For our close, we create the file that will hold the worksheet.
@Override
public void close() throws ItemStreamException {
if (wb == null) {
return;
}
createFooterRow();
try (BufferedOutputStream bos = new BufferedOutputStream(resource.getOutputStream())) {
wb.write(bos);
bos.flush();
wb.close();
} catch (IOException ex) {
throw new ItemStreamException("Error writing to output file", ex);
}
row = 0;
}
Before we write to the file and close the worksheet, we can add any additional data to the worksheet, such as formulas. You may have noticed that we have a column in the Write for a Price. Obviously, this is something that was looked up in the Processor and added to the Order object.
We could track that value in our process and write the total on the footer line. But since we are using Excel, let’s have it do the work for us.
private void createFooterRow() {
HSSFSheet s = wb.getSheetAt(0);
HSSFRow r = s.createRow(row);
Cell c = r.createCell(3);
c.setCellType(CellType.FORMULA);
c.setCellFormula(String.format("SUM(D3:D%d)", row));
row++;
}
So we add a function for summing the price column to our Excel sheet. This gives us the added benefit that if someone modifies the prices in the file later, the total will be updated automatically, as should be done in a spreadsheet.
Here is what the output looks like:

Final Thoughts
I hope this has given you enough information to read and create Excel spreadsheets with Spring Batch.
If you need to have more flexibility in defining either the Reader or Writer, both work well with the Delegate pattern I introduce here https://keyholesoftware.com/2016/03/23/introducing-the-delegate-pattern/.
Also, the original version I wrote had sensitive data in it that I did not want to exist in “clear text” on the server even during processing. So I used the work file encryption pattern outlined in my last blog post here: https://keyholesoftware.com/2017/11/13/encrypting-working-files-locally-in-spring-batch/.
Both these patterns work well with both the Reader and Writer.
Believe in Good Coding.
More From Rik Scarborough
About Keyhole Software
Expert team of software developer consultants solving complex software challenges for U.S. clients.
Share This Post
Join The Thousands Of Devs Who Subscribe
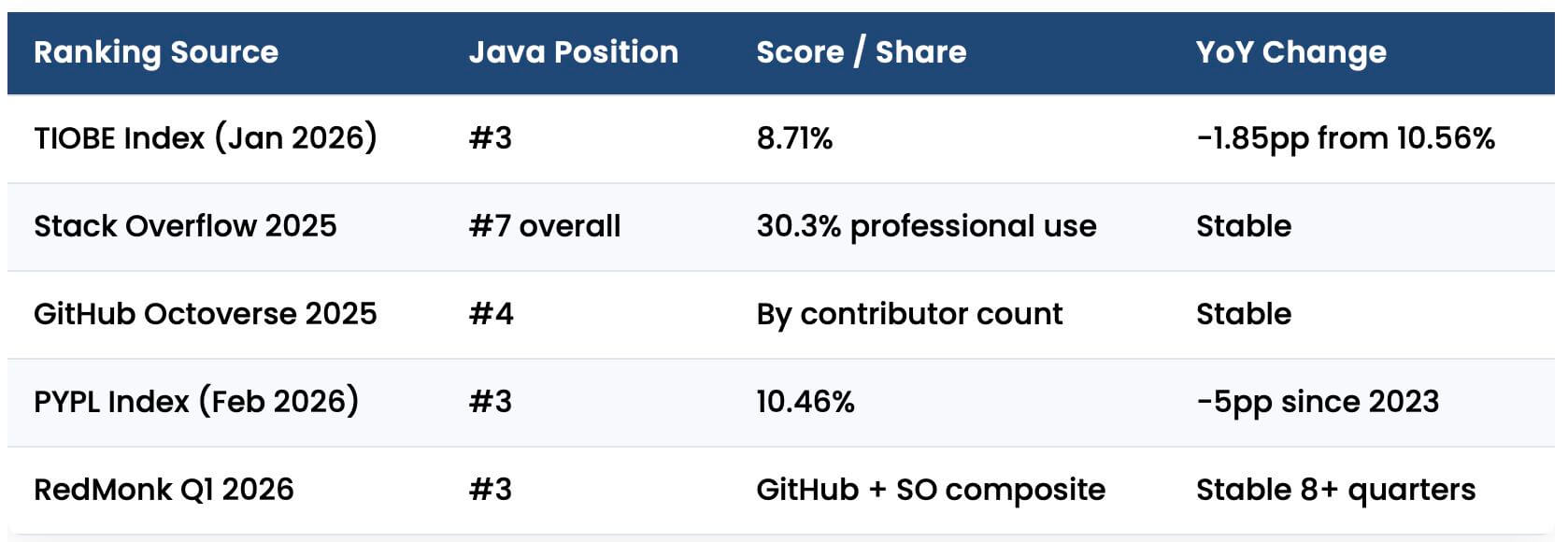


what will happen to next sheet, will it read multiple sheets?
According to the AbstractExcelItemReader, which the PoiItemReader used here inherits from, the reader will continue reading all sheets until it reads the last one. It tracks what sheet it is on in a field labeled currentSheet.
~ Rik
Is there any procedure or Websites describe hwo to run sample program “Generating Large Excel Files Using Spring Batch, Part Three” using Spring Tool Suite. I have followed the steps in Part two to import the sample programs into STS, however I have no idea how to execute or run the Sample programs using STS. Thanks in advance for your help.
The above Writer does create the desired output file, although while I try to open it on my system I am getting a corrupt file error message in Excel. Can you propose any solution?
Please note below used versions:
implementation ‘org.apache.poi:poi:5.2.3’
implementation ‘org.apache.poi:poi-ooxml:5.2.3’
Also, please note that I am initializing the FileSystemResource as new FileSystemResource(java.io.File instance) but not sure if this is causing any issues. Requesting your support.